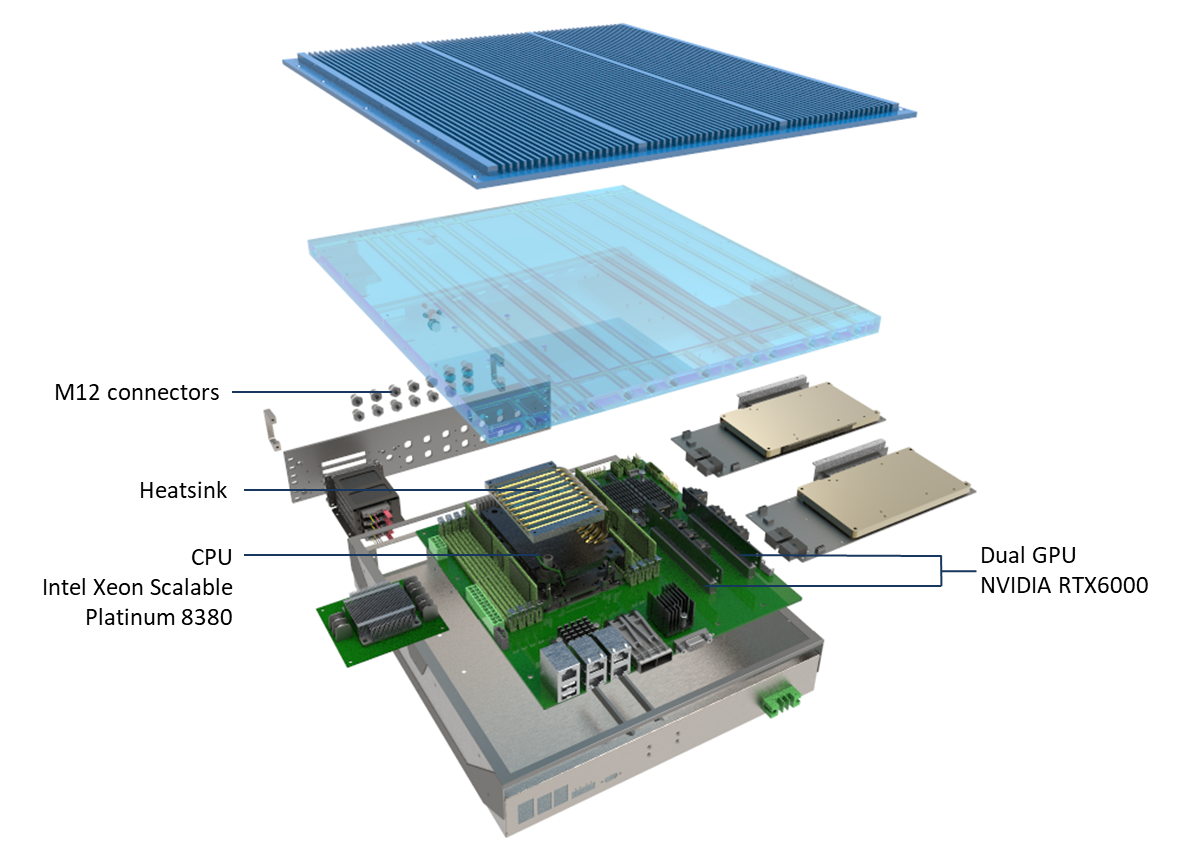
Description
The global transformation is rapidly scaling the demands for flexible computer, networking, and storage. Future workloads will necessitate infrastructures that can seamlessly scale to support immediate responsiveness and widely diverse performance requirements. The exponential growth of data generation and consumption, the rapid expansion of cloud-scale computing and 5G networks, and the convergence of high-performance computing (HPC) and artificial intelligence (AI) into new usages requires that today’s data centers and networks evolve now— or be left behind in a highly competitive environment.
7Starlake’s AV1000 AI Inference Rugged Server which are featuring 3rd Gen. Intel Dual Xeon Ice Lake Scalable Processors (40 Cores, 2.3 GHz, 270W) with 2 x NVIDIA QUADRO RTX6000, 8 x DDR4-3200MHz 2TB memory and 2 x NVMe SSD up to 48TB, to provide the seamless performance foundation for the data centric era from the multi-cloud to intelligent edge, and back. The Intel Xeon Scalable platform provides the foundation for an evolutionary leap forward in data center agility and scalability. Disruptive by design, this innovative processor sets a new level of platform convergence and capabilities across compute, storage, memory, network, and security.
AV1000 enables a new level of consistent, pervasive, and breakthrough performance in new AI inference to implement machine learning and deep learning. In addition to NVIDIA QUADRO RTX6000, AV1000 provides one M.2 NVMe slot for fast storage access. Combining stunning inference performance, powerful CPU and expansion capability, it is the perfect ruggedized platform for versatile edge AI applications.
With innovative liquid cooled design, AV1000 is built in most advanced ” Gun Drilled “, which with 10 pipes (each pipe 5mm x 5mm x \pi x 500mm) to dissipate max 10KW heat.

NVIDIA QUADRO RTX6000
The demand for visualization, rendering, data science and simulation continues to grow as businesses tackle larger, more complex workloads than ever before. However, enterprises looking to scale up their visual compute infrastructure face mounting budget constraints and deployment requirements.
Meet your visual computing challenges with the power of NVIDIA® Quadro® RTX™ GPUs in the data center. Built on the NVIDIA Turing architecture and the NVIDIA RTX platorm, the NVIDIA Quadro RTX 6000 passively cooled graphics board features RT Cores and multi-precision Tensor Cores for real-time ray tracing, AI, and advanced graphics capabilities. Tackle graphics-intensive mixed workloads, complex design, photorealistic renders, and augmented and virtual environments at the edge with NVIDIA Quadro RTX, designed for enterprise data centers.
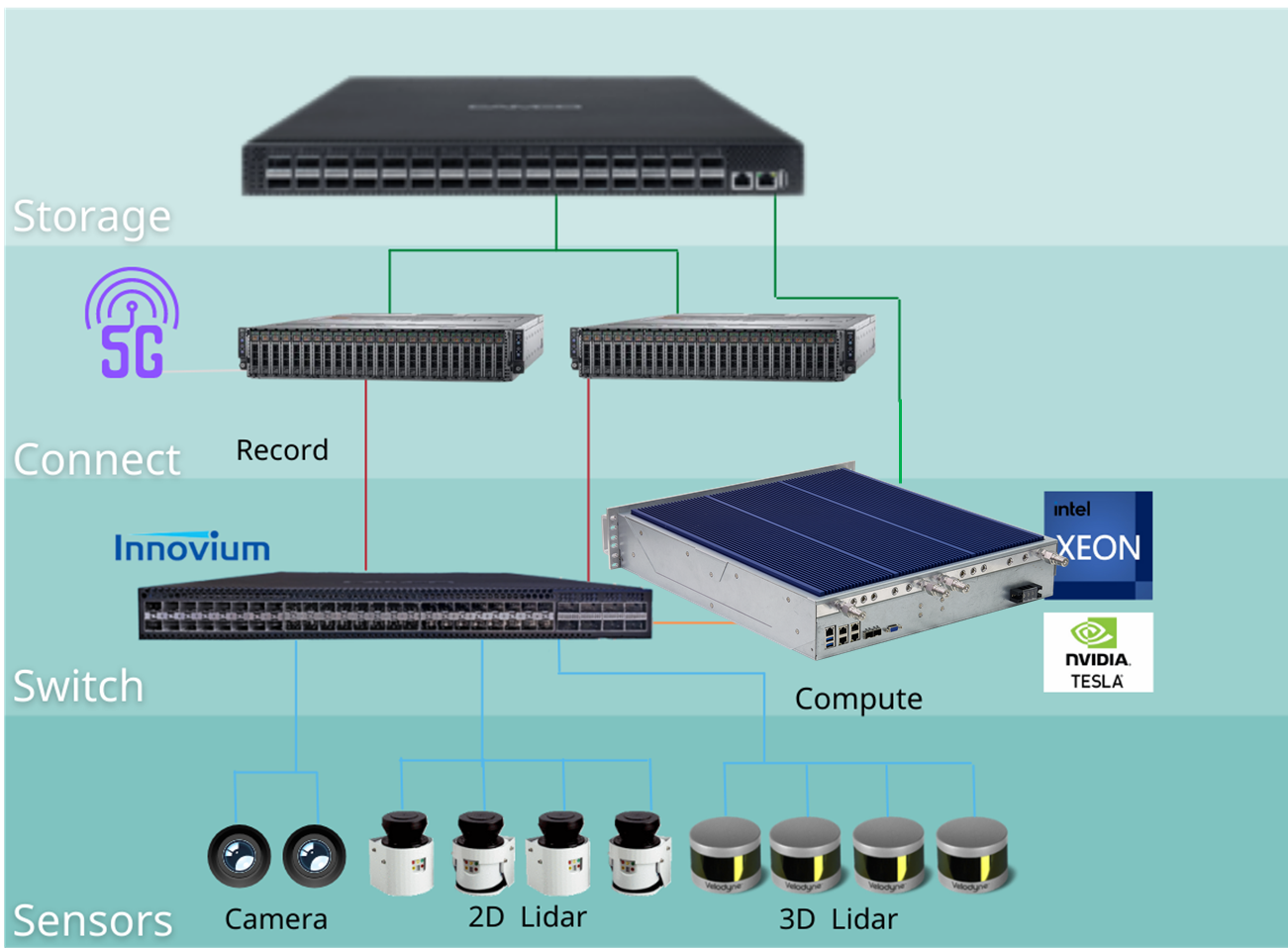
How to Leverage NVMe for AI & Machine Learning Workloads
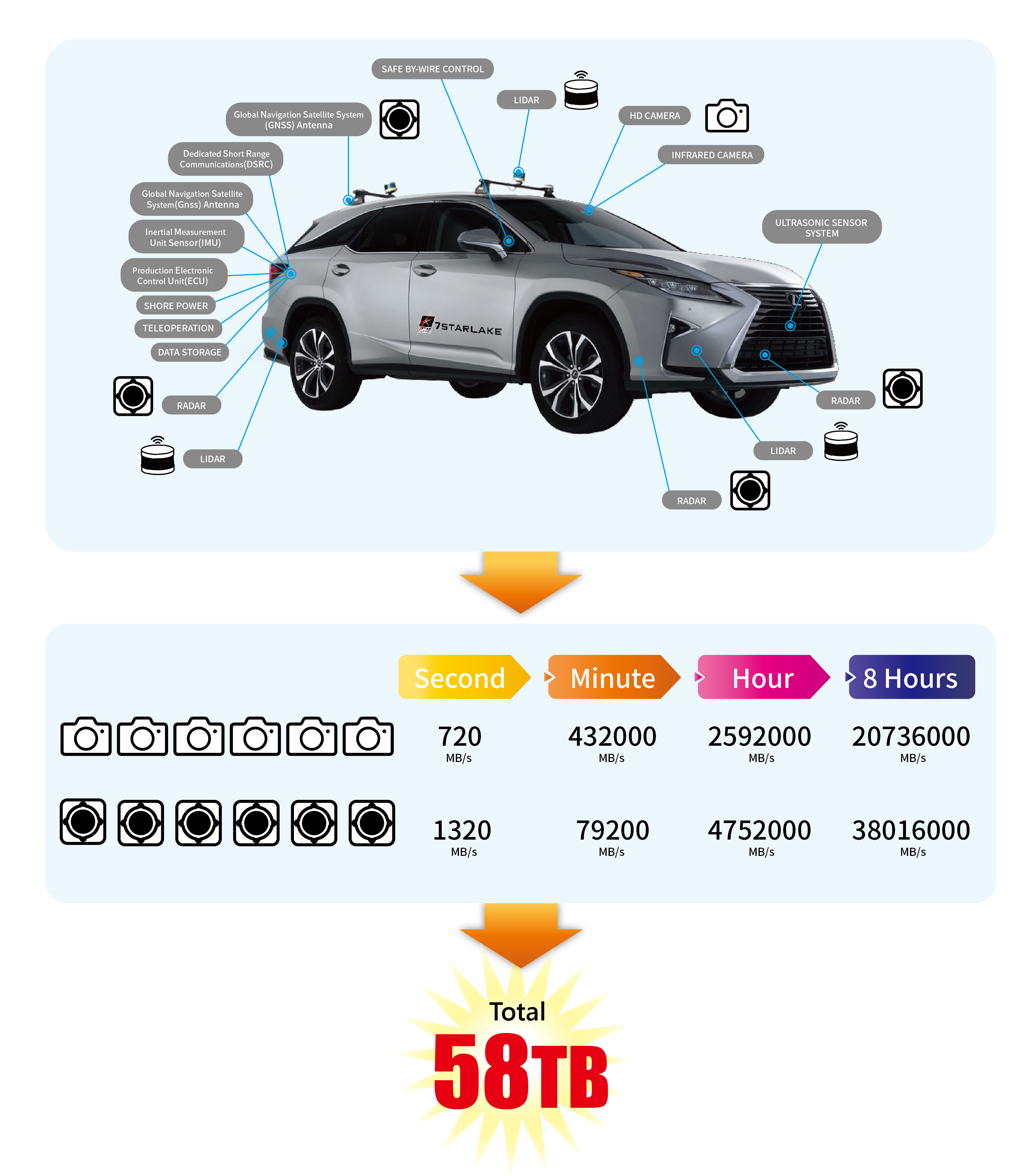
The massive amount of data which is collected from approaches mentioned above is requested for further purpose. Driverless vehicles training can employ the sorted data for future improvement and progressively enhance the road safety and further development, and this occupies the most data. An instrumented vehicle can consume over 30TB of data per day while a fleet of 10 vehicles can generate 78PB of raw data. Normally, the data rate of a camera is approximately 120MB/s while that of radar is close to 220 MB/s. To sum up, if a vehicle has a combination of 6 cameras and 6 radars, the complete vehicle RAW data will roughly be 2.040 KB/s, which is around 58TB in an 8 hour test drive shift.

The modern datasets used for model training can be up to terabytes each. Even if the training itself runs from RAM, the memory should be fed from non-volatile storage, which has to support very high bandwidth. In addition, paging out the old training data and bringing in new data should be done rapidly to keep the GPUs from being idle. This necessitates low latency, and the only protocol allowing for both high bandwidth and low latency like this is NVMe.
Fortunately, GPU servers have massive network connectivity. They can ingest as much as 48GB/s of bandwidth via 4-8 x 100Gb ports – playing a key part in one of the ways to solve this challenge.
NVMesh enables the chipset, core count, and power to be customized to match varying data workload and performance requirements. Combined with the Ultrastar Serv24-4N, NVMesh allows GPU optimized servers to access scalable, high performance without sacrificing performance and practicality. NVMe flash storage pools as if they were local flash. This technique ensures efficient use of both the GPUs themselves and the associated NVMe flash. The end result is higher ROI, easier workflow management and faster time to results.
NVIDIA QUADRO RTX6000
The demand for visualization, rendering, data science and simulation continues to grow as businesses tackle larger, more complex workloads than ever before. However, enterprises looking to scale up their visual compute infrastructure face mounting budget constraints and deployment requirements.
Meet your visual computing challenges with the power of NVIDIA® Quadro® RTX™ GPUs in the data center. Built on the NVIDIA Turing architecture and the NVIDIA RTX platorm, the NVIDIA Quadro RTX 6000 passively cooled graphics board features RT Cores and multi-precision Tensor Cores for real-time ray tracing, AI, and advanced graphics capabilities. Tackle graphics-intensive mixed workloads, complex design, photorealistic renders, and augmented and virtual environments at the edge with NVIDIA Quadro RTX, designed for enterprise data centers.
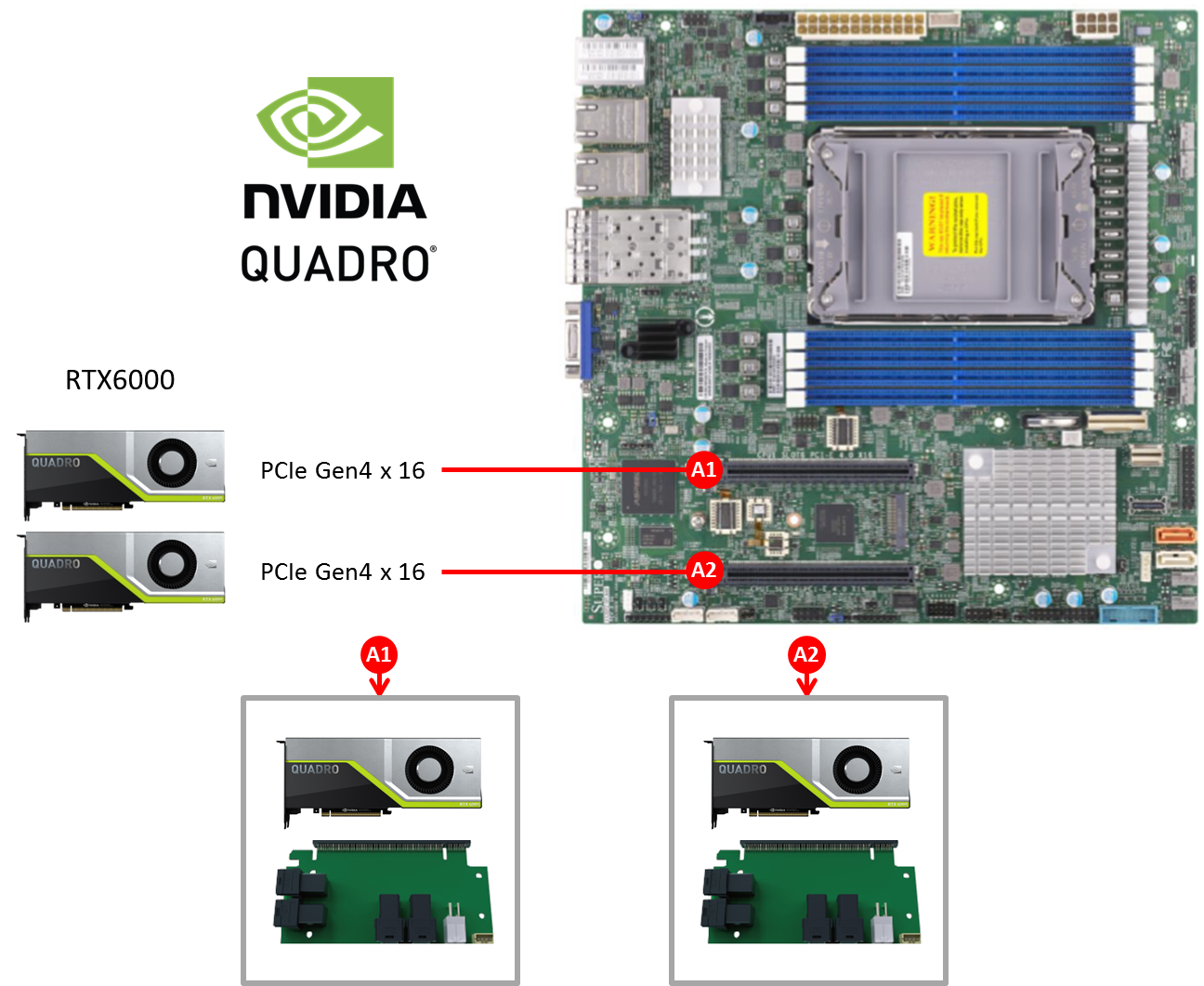
How AV1000 support 48TB NVMe
PCIe Gen 4 is the upper version of PCIe Gen 3, which surpassed PCIe Gen 2 and Gen 1. The bandwidth provided by PCIe Gen 4 is double as compared to PCIe Gen 3. It is backward compatible with prior generations of PCIe. PCIe Gen 4 is expected to satisfy, to a large extent, the requirements of high speed servers, gaming, graphics and data centers, where number of servers and solid-state devices are increasing as per market demand. PCIe Gen 4 is the new evolution over the PCIe Gen 3. The PCIe Gen 4 provides the data rate of 16 G/Ts as compared to 8G/Ts provided by PCIe Gen 3. It’s architecture is fully compatible with all the previous generations of PCIe.